

Automatic speech recognition (ASR) is the translation of spoken words into text. Speech recognition has many applications such as virtual speech assistants (e.g., Apple’s Siri, Google Now, and Microsoft’s Cortana), speech-to-speech translation, voice dictation and etc.
As shown in Fig. 1, an ASR system has five main components: signal processing and feature extraction, acoustic model (AM), language model (LM), lexicon and hypothesis search. The signal processing and feature extraction component takes the audio signal as the input, enhances the speech by removing noises and extracts feature vectors. The acoustic model integrates knowledge about acoustics and phonetics, takes the features as its input, and recognize phonemes. Language model contains information about structure of the language. Lexicon includes all words that audio signal can be mapped to them. The hypothesis search component combines AM and LM scores and outputs the word sequence with the highest score as the recognition result.
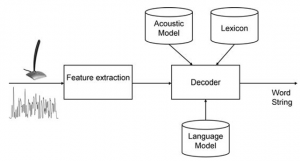
Fig 1- Speech Recognition Components
There are several methods for creating acoustic model, such as hidden markov model (HMM) [5] and artificial neural network (ANN) [1]. Audio signals as a sequential data, current input depends on previous inputs. Recurrent neural networks (RNNs) [1] benefits for their ability to learn sequential data. But for standard RNN architectures, the range of context that can be in practice accessed is quite limited. This problem is often referred to in the literature as the vanishing gradient problem. In 1997, after introducing long short term memory (LSTM) [1-3] neural network, the problem of limitation in processing sequential data resolved. An LSTM network is the same as a standard RNN, except that units in the hidden layer are replaced by memory blocks, as illustrated in Fig 2.

 Fig 3- An LSTM memory block [1]
Fig 3- An LSTM memory block [1]
One shortcoming of conventional RNNs is that they are only able to make use of previous context. In speech recognition, there is we can also benefits from future context as well. Bidirectional RNNs (BRNNs) [6] do this by processing the data in both directions with two separate hidden layers, which are then fed forwards to the same output layer. The structure of BRNN is shown in Fig 4.

Fig 4- A Bidirectional RNN [4]
A deep neural network (DNN) [5] is an ANN with multiple hidden layers of units between the input and output layers that provide a complex and nonlinear modeling. In this project, we use deep bidirectional LSTM neural (DBLSTM) [4] network for implementing a Persian ASR system. The structure of deep bidirectional LSTM is shown in Fig 5.

Fig 5- Deep Bidirectional LSTM [4]
Some related references are:
[1] Graves, A., Supervised sequence labelling with recurrent neural networks. Vol. 385. 2012: Springer.[2] Gers, F., Long short-term memory in recurrent neural networks. Unpublished PhD dissertation, École Polytechnique Fédérale de Lausanne, Lausanne, Switzerland, 2001.[3] Hochreiter, S. and J. Schmidhuber, Long short-term memory. Neural computation, 1997. 9(8): p. 1735-1780.[4] Graves, A., N. Jaitly, and A.-r. Mohamed. Hybrid speech recognition with deep bidirectional LSTM. in Automatic Speech Recognition and Understanding (ASRU), 2013 IEEE Workshop on. 2013. IEEE[5] Yu, D. and L. Deng, Automatic Speech Recognition. Signals and Communication Technology. 2015: Springer London[6] Schuster, M. and K.K. Paliwal, Bidirectional recurrent neural networks. Signal Processing, IEEE Transactions on, 1997. 45(11): p. 2673-2681.



